Why Vision-Based Web Agents Fail — and What Semantic Geometry Fixes
Vision models are good at seeing, but agents fail at acting. This post explains why vision-first web agents break down in practice, and how semantic geometry enables reliable execution.
The Problem Isn't Reasoning — It's Execution
Most modern web agents don't fail because they can't reason.
They fail because they can't act reliably.
Given a task like "search for a laptop on Amazon," today's agents typically follow this loop:
- Take a screenshot
- Ask a vision model what to click
- Guess a bounding box
- Click
- Retry when it fails
This works in demos. It breaks down in production.
The reason is subtle but fundamental: vision models were never designed to produce a stable, executable action space.
Vision Models Answer the Wrong Question
Vision models are excellent at answering questions like:
- What objects are visible?
- What text appears on the screen?
- What does this interface look like?
But agents don't need descriptions. Agents need decisions.
An agent must answer questions like:
- Which element is clickable?
- Which input accepts text?
- Which element is visible, enabled, and primary?
- Where exactly is it, in document coordinates?
- Will this decision still be valid on the next run?
What Vision Models Lack
Vision models have no native concept of:
- Action affordance
- UI roles
- Visibility vs occlusion
- Deterministic targeting
So agents built on vision are forced into probabilistic guessing + retries.
Why "Labeling the Screenshot" Doesn't Help
A common workaround is to label every element with bounding boxes and IDs, then ask the model to pick one.
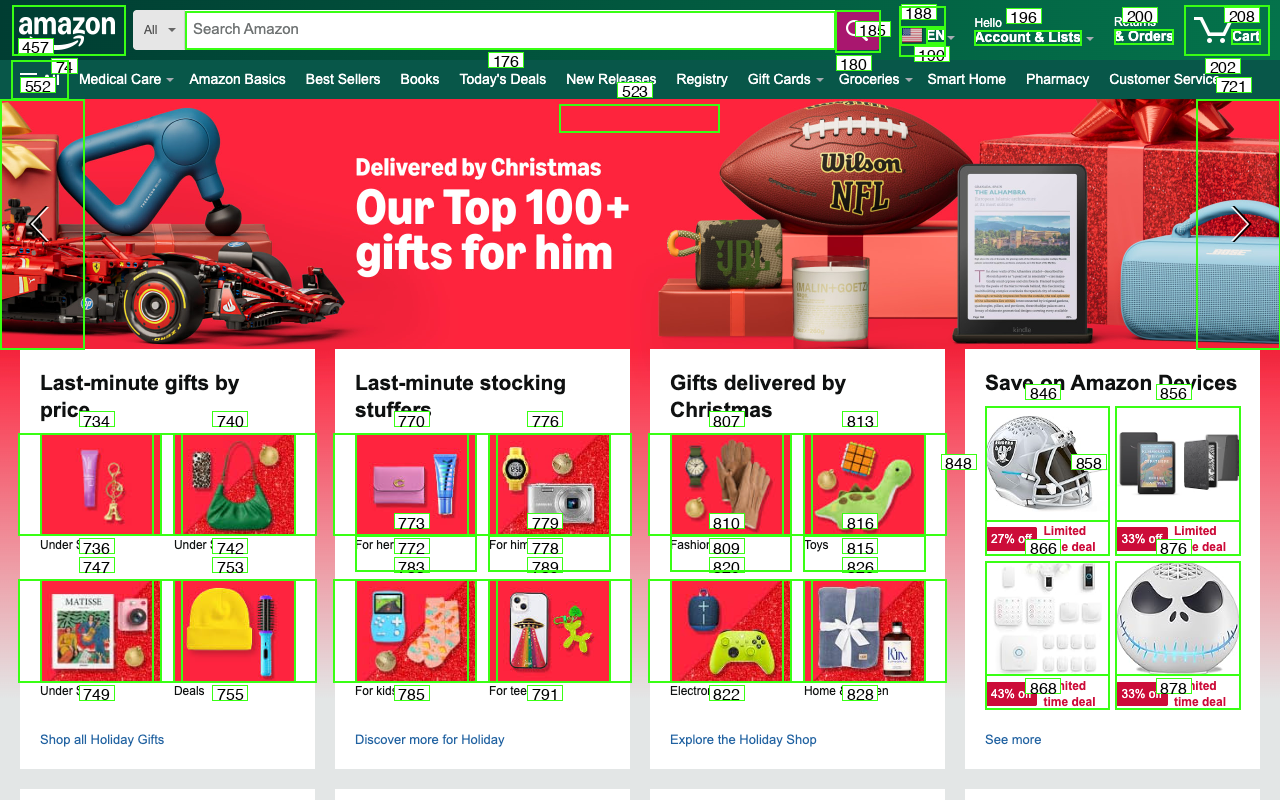
In practice, this makes things worse.
- Numeric labels have no semantic meaning
- Dense overlays destroy visual hierarchy
- Every element looks equally important
- The model must ground intent to an arbitrary symbol
Instead of choosing an action, the model is solving a brittle symbol-matching problem.
This is why labeled screenshots consistently underperform—even with large, capable vision models.
Execution Requires a Bounded Action Space
Reliable agents don't need more perception. They need less ambiguity.
What actually works is giving the model a curated set of valid actions:
- Semantic role (button, textbox, link)
- Normalized text
- Visibility and occlusion signals
- Stable geometry
- Deterministic identifiers
- Priority signals (e.g. primary action)
Now the model isn't guessing where to act. It's choosing what to do next from a constrained, executable set.
That's the difference between perception and execution.
Semantic Geometry: Turning Pixels into Actions
SentienceAPI approaches the problem differently.
Instead of asking a model to infer actions from pixels, we:
- Extract raw geometry from the browser
- Compute semantic grounding (roles, visibility, affordances)
- Rank elements deterministically
- Present the agent with an action-ready map
The output isn't a screenshot. It's an execution surface.
This allows agents to:
- Act deterministically
- Avoid retries
- Reduce token usage
- Remain stable across runs
- Be debugged and replayed step by step
Why This Matters in Production
Vision-first agents can appear impressive in short demos, but they fail under real-world conditions:
Real-World Failure Modes
- Dense pages — Hundreds of overlapping elements
- Ads and dynamic content — Shifting layouts
- Subtle UI changes — Version updates break agents
- Long-running tasks — Compounding errors
- Reliability requirements — Production needs determinism
Execution requires structure, not inference.
If an agent must act reliably, the action space must be explicit.
Seeing vs Acting
Vision models are great at seeing. Agents must act.
SentienceAPI exists to bridge that gap—by replacing probabilistic perception with deterministic execution.
If you care about reliability, retries, cost, and debuggability, vision alone is not enough.
Execution needs grounding.
Build Agents That Actually Work
Stop fighting with vision models. Get deterministic, semantic geometry for production agents.
Try SentienceAPI Free